We have been developing a vision-based hand tracker which can track a rapidly moving and deformed human hand in complicated backgrounds from a monocular camera image inputs. We implemented two methods for different applications of hand tracking. For classification of hand gestures or sign-language words in which the hand moves and is deformed so rapidly, we built a shape transition network which enables to predict hand motions and shape changes. For more precise measurement of hand shape in 3-D, we implemented a quasi real-time tracking system based on 2-D appearance matching using 3-D hand model.
Tracking Hand with Rapid Motion and Gesture Classification using Shape Transition Network
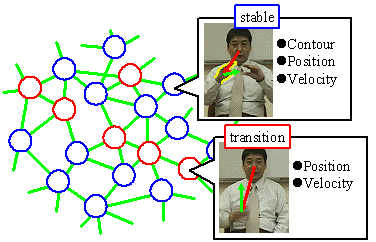
In the human gesture like sign-language, the motion and shape deformation of hand is often so rapid that the captured image is temporally blurred and too difficult to track continuously. However, hand is almost static when the hand shape is important to show the meaning of the gesture. On the other hand, the shape is not much important when the motion is meaningful in the gesture. On that viewpoint, we built a transition network which represents possible shape, position and motion change. Hand position, motion and shape (if possible) are extracted from each image frame of training movies and stored as “stable” nodes storing hand shape (contour of the hand region), position and motion, or as “transition” nodes without shape when hand is blurred. Then they are clustered into representative nodes and connected to each other by a link if they come from successive image frames of a movie. Tracking starts from a certain initial state given in advance, and the well-matched node is searched for in neighborhood of the current node on the network. Multiple hypotheses are tracked in parallel for robust tracking.
 |
 |
| Shape Transition Network: blue circles are “stable” nodes and red ones are “transition” nodes. | Tracking result video |
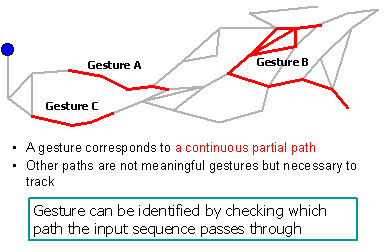
For classification of gestures, each training image sequence is embedded onto the network. By mapping each frame of the training sequence to a network node a gesture path is stored on the network. If multiple training sequences are available for one gesture class, all of them are stored. Then the gesture classification can be done by checking which path the tracked node passes through.
 |
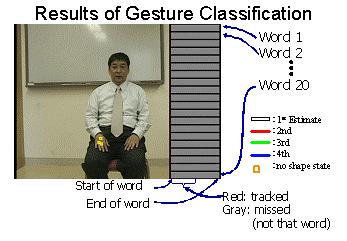 |
| Embedded gestures: each gesture is represented as a partial path on the network. If multiple training sequences are available (gesture B) all of them are stored. | Gesture classification result movie: Estimated nodes are overlaid on the input image: the 1st confident hypothesis is shown as a white line, 2nd, 3rd and 4th ones as red, green and blue lines respectively. The “transition” nodes are shown as yellow squares. Progress bars on the right edge of the movie are confidence of each embedded gesture for the input. In the video, the player shows 7 Japanese Sign Language words from “word 1” to “word 7”. You can see that all gesture have equal confidence at the beginning of each gesture but the correct one finally reaches to the end of word. For some words two models are activated simultaneously due to the two words have similar appearances. |
3-D Hand Pose Estimation based on Appearance Matching by Considering Deformation Feasibility
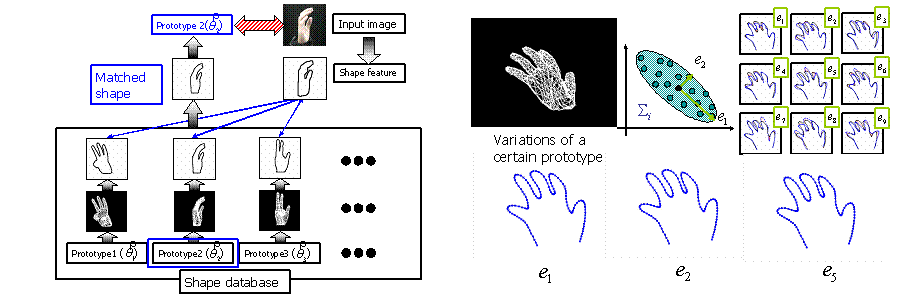
For more precise posture estimation such as the measurement of joint angles of each finger, we developed a 3-D model-based pose estimation system. The system stores many possible CG hand generated from 3-D hand model as “model appearances” changing the pose parameters (i.e. each joint angles and viewing orientation). Since each appearance is bound to the pose parameters which generate that appearance, the pose parameters for the input image can be retrieved by matching the model appearances to the input appearance. Because of very high degree of freedom of human hand, it requires huge storage space to store all possible appearances in quite precise intervals and to match them to the input. Therefore the system sparsely stores the appearances with their feasible deformation classes and evaluates the matching degree considering the feasible deformation of each appearance.
 |
|
| Overview of the pose estimation by appearance matching | Feasible deformation class for a certain model appearance (prototype): a fixed number of points are sampled on the hand contour as the appearance feature. Then collect vectorized features by slightly changing the 3-D model parameters around the prototype. By applying PCA (Principal Component Analysis), the eigenspace is obtained as the representation of the feasible deformation for the prototype. Eigen vectors are shown in the figure. [ e1 deformation animation e2 deformation animation e3 deformation animation ] In the current implementation, we use 20 dimensions with the largest eigenvalues. |
 |

|
| Estimated 3-D shapes for various hands: left images of image pairs are inputs and right ones are the estimates. | (top) Pose estimation movie by a real-time estimation system. The system is implemented on a PC-cluster hardware which consists of 16 PC nodes (PIII 1GHz and 2GB memory).
(bottom) System working scene. Real-time estimation is established. This version assumes that the wrist position is easily extracted by an extra cloth (black sleeve). The latest version can automatically extract the wrist without any extra cloth. |

 |
 |
| (left and right) An extension to complicated backgrounds. This version extracts the visual cues of intensity edges and skin color regions and then matches the model’s silhouette and occluding boundaries of each part to the visual cues. These are offline processing results. | |
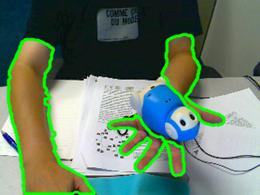
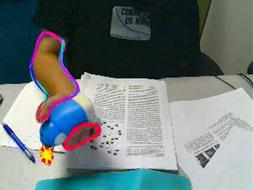
Current work
A hand often grasps an object on the desk or operates a tool. The current work of this project is to detect hand grasping objects in desktop scenes. For such scenes, the hand contour is not completely extracted or false contours are obtained due to occlusion by the grasped objects. In addition skin color region are unstable features that the contours are perturbed under various illumination conditions. We are considering that combination of partial visible contours make feasible hypothesis of hand position and pose.
 |
 |
 |