AAM Fitting Algorithms

This Project is no longer active.
We have been developing a variety of algorithms for fitting Active Appearance Models (AAMs) [Cootes, Edwards, and Taylor, 2001].
Fitting 2D Active Appearance Models
Our first algorithm, first introduced in CVPR 2001, was an analytically-derived gradient-decent algorithm, based on our “inverse compositional” extension to the Lucas-Kanade algorithm. Compared to previous numerical algorithms, we showed our algorithm to be both more robust and faster. On a 3GHz PC, the algorithm runs around 230 frames-per-second. Two example movies illustrating our algorithm are included below.
 |
 |
| Top left: the input video sequence. Top right: the input image is overlaid with the fit AAM mesh. Bottom left: the model reconstruction overlaid on the original data (highlighted to show the model more clearly). Bottom right: the model reconstruction from the fitted model parameters. |
|
Fitting Combined 2D+3D Active Appearance Models
More recently, we have extended our 2D algorithm to fit “Combined 2D+3D Active Appearance Models,” a extension of an AAM that has both a 2D and a 3D shape model, thereby having the benefits of both. On a 3GHz PC, our 2D+3D algorithm runs around 280 frames-per-second. This is even faster than the 2D algorithm because less iterations are required per frame. This speed-up illustrates the more constrained nature of fitting a 3D model. Two example movies illustrating our algorithm are included below. The one on the left demonstrates the model being fit to a collection of single images. The one of the right demonstrate the algorithm being used to track a face through a video sequence.
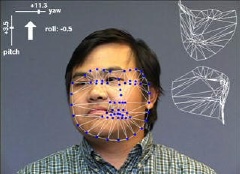 |
 |
| Left displays the 3D pose (yaw / pitch / roll). Right displays the estimated 3D shape from two different viewpoints. |
|
Fitting Active Appearance Models With Occlusion
We have also extended our algorithm to fit with occlusion. Our algorithm can handle both self-occlusion caused by large head rotation and by other occluding objects. Our algorithm operates around 50 frames-per-second on a 3GHz PC and relies on further extensions to the inverse compositional image alignment algorithm. Two example movies illustrating our algorithm are included below.
 |
 |
| The left frame in each sequence displays the results of our original 2D AAM fitting algorithm. The right frame displays the results of the extension to fit with occlusion. |
|
Generic vs. Person Specific Active Appearance Models
Anecdotal evidence suggests that the performance of an AAM built to model the variation in appearance of a single person across pose, illumination, and expression (Person Specific AAM) is substantially better than the performance of an AAM built to model the variation in appearance of many faces, including unseen subjects not in the training set (Generic AAM). We performed an empirical evaluation that shows that Person Specific AAMs are both easier to build and more robust to fit than Generic AAMs. Moreover, we showed that: (1) building a generic shape model is far easier than building a generic appearance model, and (2) the shape component is the main cause of the reduced fitting robustness of Generic AAMs. We proposed two refinements to Generic AAMs to improve their performance: (1) a refitting procedure to improve the quality of the ground-truth data used to build the AAM and (2) a new fitting algorithm. The following graphs compare the average rate of convergence for the original AAM fitting algorithm (Original PO) and the new fitting algorithm (Refit SIC) for shape and appearance models of varying size demonstrating vastly improved fitting performance.
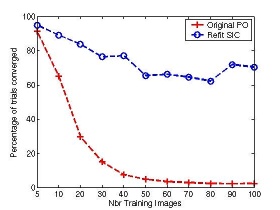 |
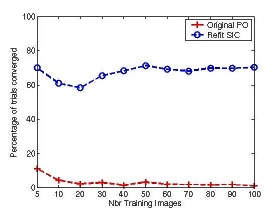 |
| Varying Shape Model Size | Varying Appearance Model Size |
Fitting an AAM to Multiple Images
A recently proposed extension of AAMs to multiple images is the Coupled-View AAM. Coupled-View AAMs model the 2D shape and appearance of a face in two or more views simultaneously. The major limitation of Coupled-View AAMs, however, is that they are specific to a particular set of cameras, both in geometry and the photometric responses. We have derived an algorithm to fit a single combined 2D+3D AAM to multiple images, captured simultaneously by cameras with arbitrary geometry and response functions. Our algorithm retains the major benefits of Coupled-View AAMs: the integration of information from multiple images into a single model, and improved fitting robustness. It can be used with any number and locations of cameras. Two example movies illustrating our algorithm are included below. The one on the left demonstrates the model being fit to a triplet of images. The one on the right demonstrates the algorithm being used to track a face through a set of 3 simultaneously captured video sequences.
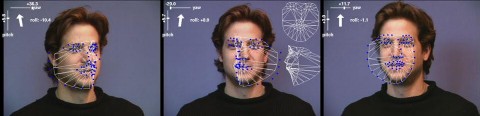 |
|
| Left Frame: Camera 1 Middle frame: Camera 2 Right frame: Camera 3 |
|
Fitting AAMs to low resolution images
We have also investigated the problem of fitting AAM’s to low resolution images. This lead us to revisit the formulation of the problem. Traditional fitting algoritms minimize the L2 norm error between the model instance and the input image warped onto the model coordinate frame. While this works well for high resolution data, the fitting accuracy degrades quickly at lower resolutions. We showed that a careful design of the fitting criterion can overcome many of the low resolution challenges. In our “resolution-aware formulation” (RAF), we explicitly account for the finite size sensing elements of digital cameras, and simultaneously model the processes of object appearance variation, geometric deformation, and image formation. In the figure below, the top row shows lower and lower resolution input images for testing. The middle row shows reconstructed faces using the RAF fitting results. As shown in the bottom row, one cannot recover their visual details as well using the traditional formulation. RAF significantly improves the estimation accuracy of both shape and appearance parameters when fitting to low resolution data.

current head

current staff

current contact
past head
- Simon Baker
past staff
- Ralph Gross
- Takahiro Ishikawa